输入URL到显示网页 全过程解析
最后一次更新时间:Monday, December 28th 2020, PM
打开浏览器,在地址栏中输入一串英文,敲一下回车键,就会显示出对应的网页。自从万维网问世,这一套操作流程就流传至今。可以说,只要是会用电脑的人,就一定会这一套操作。那么就是这样一个不起眼却必备的技能,其背后的原理究竟是怎样的?
首先,我们打开浏览器,在地址栏中输入一串英文。以我的个人网站为例www.ryanyhliu.com,这一串英文我们称其为域名。所谓域名,就是网站的代号,那么网站是什么呢,网站可以理解为是某台存储有该网页的电脑。
1 | |
所以说,在浏览器的地址栏中输入www.baidu.com与183.232.231.172,都可以访问百度。(我的网站加了安全保护,不支持IP直接访问,故以百度为例)
在地址栏中输入域名时,浏览器会基于本地的历史记录、书签等进行自动补全,如下图所示。
我们接着看。输入完网址按下回车,会发现地址栏中填入的信息变成了https:// + 域名

可以发现,浏览器在域名前面自动添加了https://这样一个前缀。我们把地址栏中这一整个英文串称为URL(Uniform Resource Locator 统一资源定位符)。这个补全的过程是自动的,我们只需要输入域名,浏览器会自动添加前缀(不一定是https)。
那么这个前缀是什么含义呢?HTTP是一种传输协议,其全称为HyperText Transfer Protocol(超文本传输协议)。它是用来传输及显示网页的一个标准,你可以理解为文件的拓展名机制。系统通过识别拓展名,就知道该文件是如何编码的,从而进行相应的解读并显示给用户。HTTPS则是在HTTP的基础上,添加了SSL层。更详细的部分在我的这篇博客中有介绍:HTTP相关 && 对称/非对称加密简述
好了,按下回车。此时,浏览器进行的是将域名转换为IP地址的工作。
浏览器首先查看本地的Hosts文件在Windows中,该文件存储目录为C:\Windows\System32\drivers\etc\hosts,该文件中存储了最为常用的域名与IP的映射,也是最容易被一些流氓软件篡改的文件。若该文件中查询不到该域名的IP,则向本地DNS服务器(Domain Name System)(网络接入服务商所提供的DNS)发送查询请求。如果本地DNS中没有缓存该记录,则发送请求到根服务器。
1 | |
根服务器返回该URL对应的域服务器IP。若第一个根服务器中没找到,则去第二个根服务器中找,此时发生的是迭代查询(同级关系);若域服务器不断向下一级服务器查找,则是递归查询(子级关系)。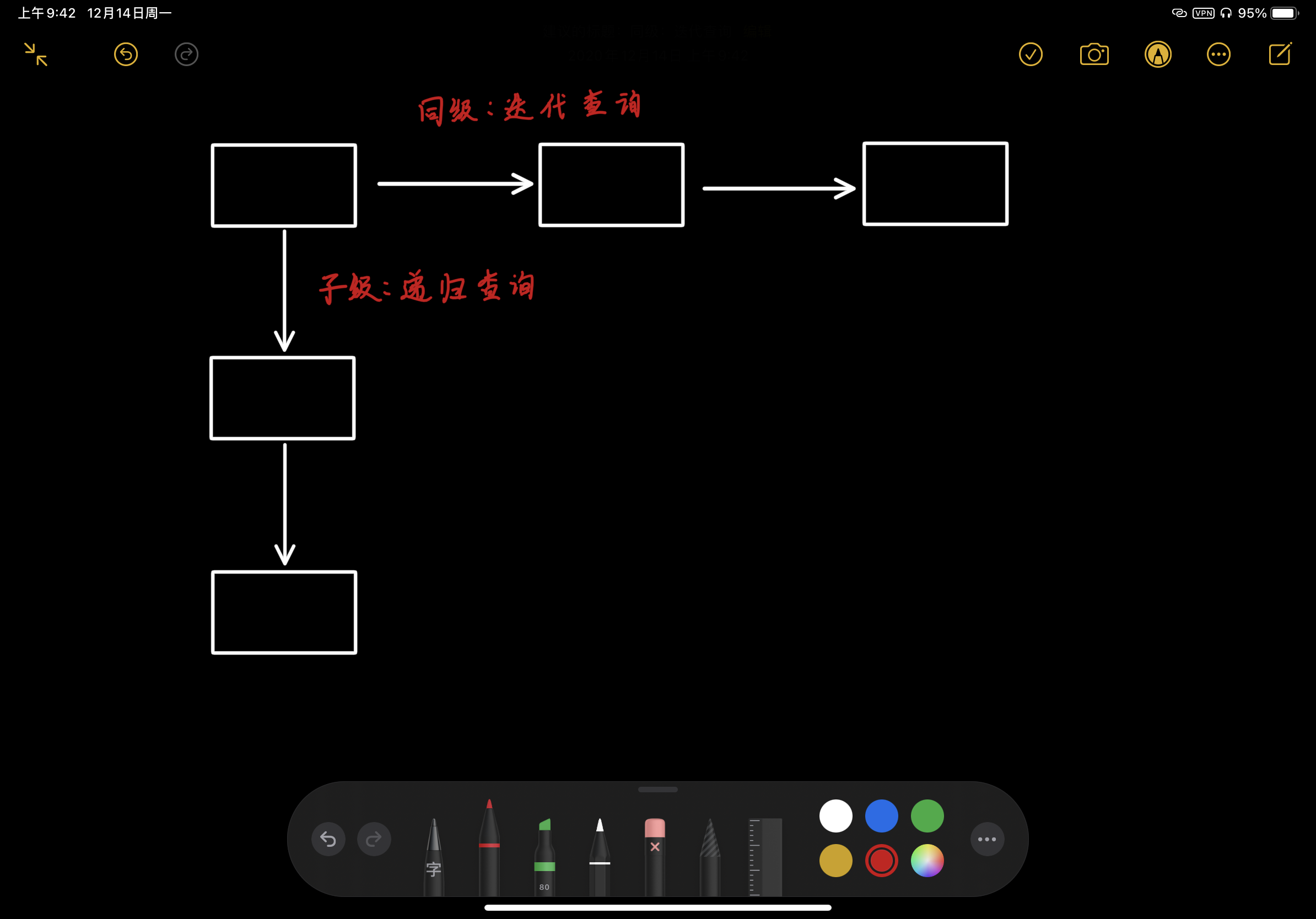
直至找到该URL所对应的IP,将其返回给本地DNS。本地DNS把该 域名——IP 映射 进行缓存,以备其它人的电脑再次查询(就不用再走根服务器了),并将IP返回给你的电脑。
此时我们拿到了IP地址,下一步就可以与网站建立连接啦!
浏览器得到IP地址之后,会以本地一个随机端口(1024~65535,左右均为开区间)建立Socket,向服务器的80端口发起TCP连接请求。该TCP连接请求通过网络路由,进入服务器网卡(还原成包,检查MAC)。然后进入服务器OS的TCP/IP协议栈(检查IP头),再被丢给Web程序,从而使服务器端也建立一个Socket,与用户的Socket三次握手,从而建立连接(建立三次握手的过程在我的这篇博客中有介绍:TCP三次握手与四次挥手)。
建立TCP链接后,发送一个HTTP请求。HTTP请求中包含了
- 请求方法
- 请求头
- 请求正文
其中请求头和请求正文之间有一行空行,不可省略,表示请求头结束。
PS:
- 如果要访问的网站设置了重定向(HTTP提供的特性,用于当前资源迁移到新URL),则要再重发一个HTTP请求。
- 如果要访问的网站设置了反向代理,例如Nginx,则该HTTP请求是发送给Nginx,Nginx再发送给某个服务器的Web程序。

服务器收到了HTTP请求后,需要进行处理并返回处理结果,该过程称为HTTP响应。HTTP响应中包含了
- 状态行(状态码在这里)
- 响应头
- 响应正文
与HTTP请求类似,在响应头和响应正文之间有一行空行,原因同上。
关于状态码的部分也可以参照我之前的博客:HTTP相关 && 对称/非对称加密简述
客户端浏览器从网站服务器处,收到以HTTP协议传输过来的HTML文件(即网页)。在还未完整接收完的时候,便已经开始将收到的部分内容显示到显示器上。
浏览器解析,显示HTML文件的过程,我们以Webkit内核的浏览器作为示例来讲解。
PS:浏览器内核简史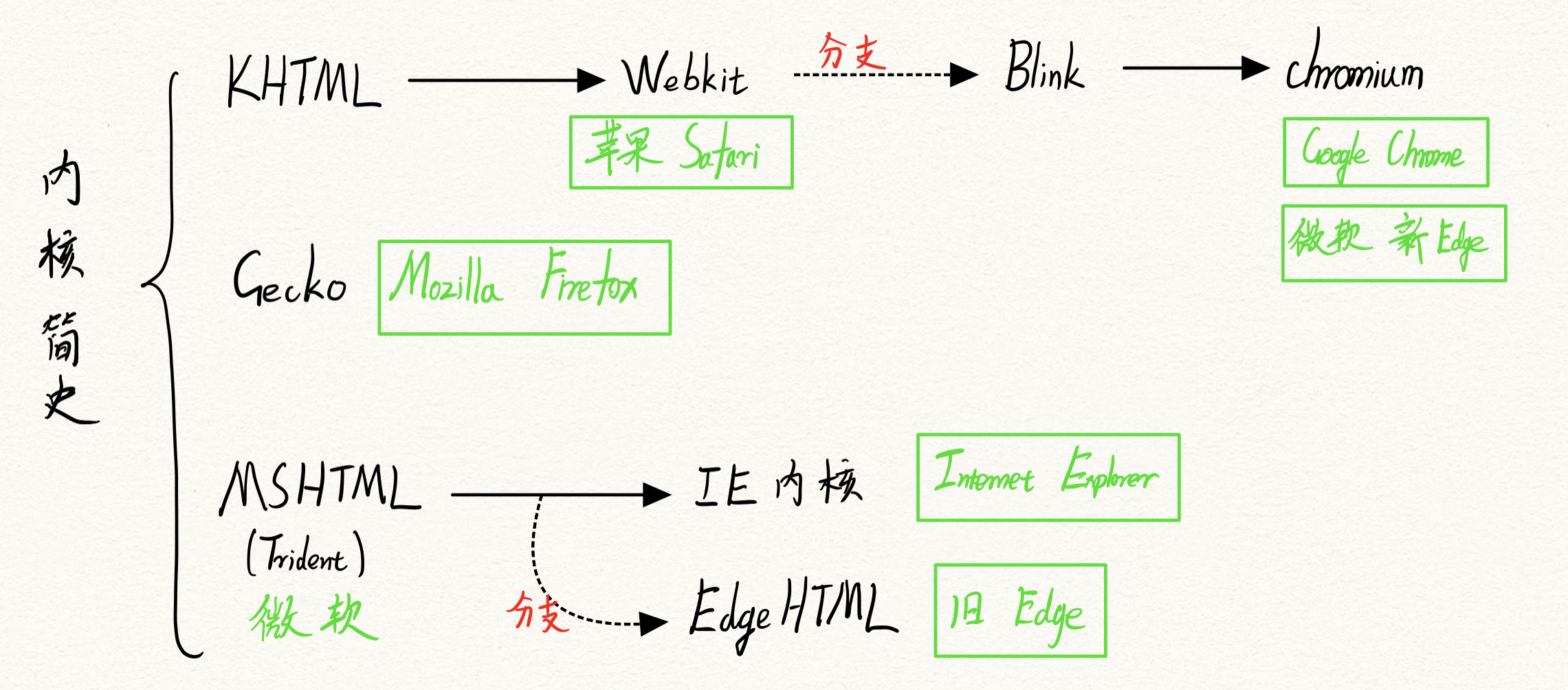
Webkit解析并显示HTML文件的过程:
- 解析HTML文件,构建DOM树
- 构建render树
- 布局render树(reflow 回流)
- 绘制render树(repain 重绘)
解析HTML文件时,自上而下,边解析边渲染。
若解析过程中需要请求外部资源——异步请求。
若解析过程中遇到js,则暂停HTML解析,进行js渲染(阻塞,所以要把js代码放在文档末尾)。
HTML文件构建完DOM树之后,再解析CSS文件构建render树。
构建完render树之后,浏览器开始布局并绘制到屏幕上(这一步会发生reflow和repain,非常消耗性能)。
这样,一个网页就呈现在屏幕上了!是不是非常简单/狗头
除特别声明外,本站所有文章均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
